André Lindenberg’s post about herdr came across my feed, and the pitch landed on something I have been living in for months:
You already run tmux to keep agents alive when you close the laptop. herdr goes further: through its socket API an agent splits a sibling pane, starts another agent, and blocks on its settled state before continuing.
My terminal is cmux — I wrote up my setup a while back, including the fight to make agent panes come back on their real conversations after a reboot. Same problem, two tools, so: an honest comparison, and an actual decision at the end rather than a shrug about a thousand flowers.
The structural difference
herdr is a daemon plus a TUI client that runs inside the terminal you already have. The daemon owns the PTYs; clients attach and detach. ctrl+b q detaches, herdr reattaches, including over SSH. macOS, Linux, Windows (beta). Rust, Apache-2.0, v0.7.5. The repo was created in late March 2026 and is at 20.8k stars — four months, from zero. That pace is not an accident and it is not a toy.
cmux is a native macOS app that embeds Ghostty as its renderer. It is the terminal, not a program running inside one. Swift, GPU rendering, vertical workspace tabs, browser panes, a notification center. GPL-3.0-or-later with a commercial option, v0.64.20, 25.1k stars.
Almost everything below follows from that one choice.
Which seat is each one optimizing?
This is the whole comparison, so I will put it before the evidence rather than after.
herdr optimizes the seat the agent sits in. agent wait --until done is a primitive for a program coordinating other programs. Occupant pinning, fused prompt-and-wait, the HERDR_ENV gate — those are the concerns of a caller that is not a person.
cmux optimizes the seat I sit in. The approval feed, notifications, browser panes, hook-recorded native session restore — those matter when a human is the scheduler and the agents are the ones asking permission.
So “which is better” resolves to “who does the scheduling in your workflow.” In mine, today, it is still me: I fan agents out, they come back with questions, I unblock them. That is a human-in-the-loop shape and cmux is built for it. The day the dominant pattern becomes agent spawns agent and blocks on it, herdr’s design is the right one.
What herdr does better
1. The wait verb. This is the real content of André’s post and the thing I would take today:
herdr agent wait w1:p1 --until doneherdr agent wait w1:p1 --until blocked
Server-owned, event-driven rather than polled, and it pins the resolved pane occupant so a replacement agent cannot satisfy the wait. agent.prompt also accepts an optional wait object, so submit-and-wait is one request with no race between the calls.
That is a genuine orchestration primitive. “Start the sibling, hand it work, block until it settles” becomes three lines of shell instead of a bespoke state machine.
cmux has the state — its hook integrations record running / idle / needsInput / unknown — and it has a durable event stream. It just does not expose a verb that joins them.
2. Detach is a real concept. cmux’s session lives in the app; herdr’s lives in a daemon you attach to. That difference is why my reboot post needed an appendix. To be fair: a power cycle kills the herdr daemon too, and nothing resurrects a dead PTY. But “close the laptop, reattach from another terminal, reattach over SSH” is a first-class flow there and a workaround-shaped thing in a GUI app.
3. It runs where the work runs. Linux boxes, remote hosts, Windows beta. cmux is macOS-only by construction. If your agents live on a build server, that is not a preference, it is a constraint.
4. Plugins are shipped surface. A herdr-plugin.toml declares startup hooks, actions, event hooks, and pane entrypoints; plugins launch as processes with HERDR_* context injected. There is a marketplace and a visible third-party ecosystem — review sidebars, file viewers, phone clients, remote mirrors. cmux’s ExtensionKit sidebars are younger and have been through at least one revert.
What cmux does better
1. It is a terminal, so it does not have to borrow one. No nested-multiplexer key contention, no arguing over ctrl+b, no “which layer ate my mouse event.” Real tabs, real drag-and-drop, GPU rendering.
2. Panes are not only PTYs. Surfaces can be terminals, browsers, markdown viewers, or file previews — and the browser is scriptable from the same CLI (cmux browser navigate|click|wait|download). An agent can be handed a rendered page and a doc alongside its shell. In herdr everything is a character grid; the nearest analog is experimental Kitty-protocol pane graphics.
3. Agent state is told, not inferred. cmux hooks setup installs session hooks for 14 agents — Claude Code, Codex, Grok, OpenCode, Pi, Amp, Cursor, Gemini, Kiro, Rovo Dev, Copilot, CodeBuddy, Factory, Qoder — and stores each one’s native resume command (claude --resume <id>, codex resume <id>, amp threads continue <id>, …), so a relaunch continues the real conversation. herdr detects state by evaluating manifests against a terminal snapshot. Detection is clever; being told is sturdier.
4. The human is in the protocol. The Feed collects permission requests and questions from every agent into one approval queue. Notifications, sidebar status pills, progress bars, and log lines are all CLI-writable by the agents themselves. herdr’s notification.show is a toast; six running agents need one blocked-list, not six toasts.
5. Remote and cloud are features, not an absence. cmux ssh creates remote workspaces with a bundled daemon and persisted PTY sessions you can list, attach, and clean up; cmux vm manages cloud VMs. Different shape from detach/reattach, but the “my agents are on another machine” case is covered.
The decision
Not “let a thousand flowers bloom.” That is what you say when you do not want to choose, and two multiplexers on one machine means two keymaps, two session stores, and two places to look for the agent that is blocked.
cmux stays the cockpit on macOS. Not because it wins on paper — on the agent-facing API it does not — but because switching cockpits costs everything built around the human loop: the approval feed, the notification wiring, hooks for 14 agents, workspace layouts, muscle memory. herdr would have to be better by a lot to clear that, and on the axis I actually sit on it is not better, it is differently good.
herdr gets adopted where cmux structurally cannot go: Linux boxes, remote hosts, SSH-first work. That is not hedging, because cmux is not competing there. It is a division of territory, not a bake-off.
No dual-running on the same Mac. If I catch myself doing it, that is evidence this split is wrong and I should re-run the comparison rather than live in both.
The tripwire, stated in advance so it is falsifiable. I switch outright if either becomes true:
- Primary development moves off macOS. Then cmux’s best feature — being an excellent native Mac terminal — is simply unavailable, and the rest is a wash.
- Agent-to-agent orchestration becomes the dominant mode — agents spawning and blocking on agents rather than me fanning out and unblocking — and cmux still has no wait verb. At that point I would be hand-rolling in event-stream shell what herdr ships as one command, which is the definition of using the wrong tool politely.
Neither is true today. Both are plausible within a year, and #2 is the one I would bet on. Review date: January 2027. A decision with no review date is just a preference.
Where a thousand flowers genuinely help is at the ecosystem level, not on my desk: herdr existing is the best argument cmux will ever get for shipping a wait verb, and cmux’s hook-based session capture is the best argument herdr will get for taking state from hooks instead of the screen. Each is holding up a mirror the other needs. I would rather have both projects than a merged one — and still pick one per machine.
What I asked of cmux
Filed, because I use it daily and can answer the follow-ups:
- #8950 — a wait verb:
cmux wait --surface <id> --until idle|needs-input --timeout <ms>, occupant-pinned, plussend --wait-untilto close the submit-then-wait race. Today the closest thing iscmux events --name agent.hook.Stop --limit 1, which matches one agent’s hook vocabulary rather than semantic state and pins nothing. - #8951 — publish agent lifecycle as an event (
agent.state.changed). Therunning/idle/needsInputstate exists but lives in~/.cmuxterm/<agent>-hook-sessions.jsonand the hibernation subsystem; it is absent from the public event catalog that already carrieswindow.*,workspace.*,surface.*, andfeed.*. It is the substrate the wait verb should be built on.
Two more that need no issue: resume bindings should stay PATH-relative rather than storing a resolved absolute path at pane creation (#6572, already fixed by #6582), and reboot restore should be a stated contract — my panes started coming back on 0.64.15 while the flag I expected to gate it was false for every pane (#5802, still open). Getting the right answer for a reason you cannot name is not a fixed bug, it is a deferred one.
What I would ask of herdr, and why it stays here
Two things would move herdr from “right tool for the remote boxes” to “candidate for the cockpit”:
Take state from hooks, not from the screen. The scaffolding exists — pane.report_agent accepts exactly that shape, pane.report_agent_session stores native session references, integration.install is there. The gap is breadth: cover agents first-party the way cmux hooks setup covers 14 of them, and let screen detection be the fallback rather than the primary path.
Give the human a queue. When six agents are running, what I need is not six toasts, it is one list of what is blocked. herdr already has the ingredients — semantic blocked state, agent.view.set projections, an agent sidebar — so this may be more assembly than invention. Both of these are things a plugin could prototype without touching the core.
I am deliberately not filing either as an issue. I have read herdr’s docs closely and have not run it in anger, and a feature request from a non-user is a maintainer tax: they have to reconstruct my context before they can even judge whether I found a real gap or just did not finish the manual. The cmux asks went to its tracker precisely because I use it daily. These stay at blog volume, where someone who actually runs herdr can correct me cheaply — and I would rather be corrected here than spend a maintainer’s triage.
One note on addressing, since the post that started this was not from the maintainer: herdr is Can Celik’s. Thanks to André for putting it in front of me — the framing in that post is what made me go read the socket API instead of skimming another launch.
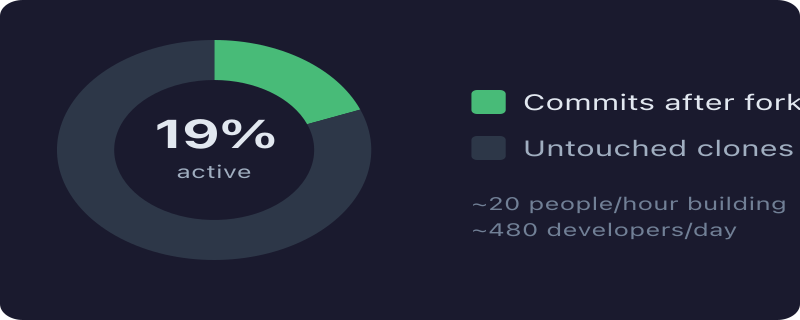
Footnote: the fork nobody was maintaining
While writing this I checked our own voitta-ai/cmux fork. It was 0 commits ahead and 3,171 behind upstream — a June snapshot with no patches on it. That is not a fork, it is a stale bookmark that quietly implies we carry local changes.
We do not, and that is correct: the cmux problems I actually hit went upstream as issues, and one is already fixed there by a maintainer. Filing beats forking whenever the maintainer is responsive — a fork you do not rebase is a liability with a nice URL. Resynced while writing this; it is identical to upstream again.
It also mattered for the two issues above. Our checkout was seven weeks stale, so I checked both proposals against upstream main before filing — “open an issue for a feature that shipped last month” is a real way to waste someone’s afternoon. Still missing on current main: wait-for remains the tmux-compat named synchronization point, and the event catalog still has nothing for agent state.
























{kind=link}