We’ve been acquired by Applovin. Onwards and upwards!
Year: 2020
FinOps
Some time ago a discussion about CIO vs CMO as it comes to ad tech started, and as I see it, it still continues. As a technical professional in ad tech space, I followed it with interest.
As I was building ad tech in the cloud (which usually involves large scale — think many millions QPS), business naturally became quite cost-conscious. It was then when, I, meditating on the above CIO-CMO dichotomy, thought that perhaps the next thing is the CIO (or the CTO) vs — or together with — the CFO.
What if whether to commit cloud resources (and what kind of resources to commit) to a given business problem is dictated not purely by technology but by financial analysis? E.g., a report is worth it if we can accomplish it using spot instances mostly; if it goes beyond certain cost, it is not worth it. Etc.
These are all very abstract and vague thoughts, but why not?
Recently I learned of an effort that seems to more or less agree with that thought — the FinOps foundation, so I am checking it out currently.
Sounds interesting and promising so far.
And nice badge too.
![]()
Ad-hoc querying on AWS: Connecting BI tools to Athena
In a previous post, we discussed using Lambda, Glue and Athena to set up queries of events that are logged by our real-time bidding system. Here, we will build on that foundation, and show how to make this even friendlier to business users by connecting BI tools to this setup.
Luckily, Athena supports both JDBC and ODBC, and, thus, any BI tool that uses either of these connection methods can use Athena!
First, we need to create an IAM user. The the minimum policies required are:
- AmazonAthenaFullAccess
- Writing to a bucket for Athena query output (use an existing one or create a new one). For the sake of example, let’s call it s3://athena.out
- Reading from our s3://logbucket which is where the logs are in
Now we’ll need the access and the secret keys for that user to use it with various tools.
JDBC
JDBC driver (com.simba.athena.jdbc.Driver) can be downloaded here.
The JDBC URL is constructed as follows:
jdbc:awsathena://User=<aws-access-key>;Password=<aws-secret-key>;S3OutputLocation=s3://athena.out;Here’s a sample Java program that shows it in action:
import java.sql.Connection;
import java.sql.DriverManager;
public class Main {
public static void main(String[] args) throws Throwable {
Class.forName("com.simba.athena.jdbc.Driver");
String accessKey = "...";
String secretKey = "...";
String bucket = "athena.out";
String url = "jdbc:awsathena://AwsRegion=us-east-1;User=" + accessKey + ";Password=" + secretKey
+ ";S3OutputLocation=s3://" + bucket +”;";
Connection connection = DriverManager.getConnection(url);
System.out.println("Successfully connected to\n\t" + url);
}
}Example using JDBC: DbVisualizer
- If you haven’t already, download the JDBC driver to some folder.
- Open Driver Manager (Tools-Driver Manager)

- Press green + to create new driver

- Press the folder icon on the right …

- … and browse to the folder where you saved the JDBC driver and select it:

- Leave the URL Format field blank and pick com.simba.athena.jdbc.Driver for Driver Class:

- Close the Driver Manager, and let’s create a Connection:

- We’ll use “No Wizard” option. Pick Athena from the dropdown in the Driver (JDBC) field and enter the JDBC URL from above in the Database URL field:
- Press “Connect” and observe DbVisualizer read the metadata information from Athena (well, Glue, really), including tables and views.

ODBC (on OSX)
- Download run ODBC driver installer
- Create or edit /Library/ODBC/odbcinst.ini to add the following information:
[ODBC Drivers]
Simba Athena ODBC Driver=Installed
[Simba Athena ODBC Driver]
Driver = /Library/simba/athenaodbc/lib/libathenaodbc_sbu.dylib
If the odbcinst.ini file already has entries, put new entries into the appropriate sections; e.g., if it was
[ODBC Drivers]
PostgreSQL Unicode = Installed
[PostgreSQL Unicode]
Description = PostgreSQL ODBC driver
Driver = /usr/local/lib/psqlodbcw.so
Then it becomes
[ODBC Drivers]
PostgreSQL Unicode = Installed
Simba Athena ODBC Driver=Installed
[PostgreSQL Unicode]
Description = PostgreSQL ODBC driver
Driver = /usr/local/lib/psqlodbcw.so
[Simba Athena ODBC Driver]
Driver = /Library/simba/athenaodbc/lib/libathenaodbc_sbu.dylib
- Create or edit, in a similar fashion, /Library/ODBC/odbc.ini to include the following information:
[AthenaDSN]
Driver=/Library/simba/athenaodbc/lib/libathenaodbc_sbu.dylib
AwsRegion=us-east-1
S3OutputLocation=s3://athena.out
AuthenticationType=IAM Credentials
UID=AWS_ACCESS_KEY
PWD=AWS_SECRET_KEY
- If you wish to test, download and run ODBC Manager. You should see that it successfully recognizes the DSN:

Example using ODBC: Excel
- Switch to Data tab, and under New Database Query select From Database:

- In the iODBC Data Source Chooser window, select AthenaDSN we configured above and hit OK.

- Annoyingly, despite having configured it, you will be asked for credentials again. Enter the access and secret key.
- You should see a Microsoft Query window.
Success!
Helpful links
- Connecting to Athena with JDBC and ODBC
- Manual for JDBC driver
- Manual for ODBC driver
Ad-hoc querying on AWS: Lambda, Glue, Athena
Introduction
If you give different engineers the same problem they will usually produce reasonably similar solutions (mutatis mutandis). For example, when I first came across a reference implementation of an RTB platform using AWS, I was amused by how close it was to what we have implemented in one of my previous projects (OpenRTB).
So it would be not much of a surprise that in the next RTB system, a similar pattern was used: logs are written to files, pushed to S3, then aggregated in Hadoop from where the reports are run.
But there were a few problems in the way…
Log partitioning
The current log partitioning in S3 is by server ID. This is really useful for debugging, and is fine for some aggregations, but not really good for various reasons – it is hard to narrow things by date, resulting in large scans. It is, therefore, even harder to do joins. Large scans in tools like Athena also translate into larger bills. In short, Hive-like partitioning would be good.
To that end, I’ve created a Lambda function, repartition, which is triggered when a new log file is uploaded to s3://logbucket/ bucket:
import boto3
from gzip import GzipFile
from io import BytesIO
import json
import urllib.parse
s3 = boto3.client('s3')
SUFFIX = '.txt.gz'
V = "v8"
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
s3obj = s3.get_object(Bucket=bucket, Key=key)
src = { 'Bucket': bucket, 'Key': key }
(node, orig_name) = key.split("/")
(_, _, node_id) = node.split("_")
name = orig_name.replace(SUFFIX, "")
(evt, dt0, hhmmss) = name.split("-")
hr = hhmmss[0:2]
# date-hour
dthr = f"year=20{dt0[0:2]}/month={dt0[2:4]}/day={dt0[4:6]}/hour={hr}"
schema = f"{V}/{evt}/{dthr}"
dest = f"{schema}/{name}-{node_id}{SUFFIX}"
print(f"Copying {key} to {dest}")
s3.copy_object(Bucket=bucket, Key=dest, CopySource=src)
return "OK"
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
if __name__ == "__main__":
# Wrapper to run from CLI for now
s3entry = {'bucket' : {'name' : 'logbucket'},
'object' : {'key' : server/requests-200420-003740.txt.gz'}}
event = {'Records' : [{'s3' : s3entry}] }
lambda_handler(event, None)
At that time, the log is copied to a new path is created under v8 prefix, with the following pattern:
<event>/year=<year>/month=<month>/day=<day>/hour=<hour>/<filename>-<nodeID>. For example,
s3://logbucket/server1234/wins-200421-000003.txt.gz
is copied to
s3://logbucket/v8/wins/year=2020/month=04/day=21/hour=00/wins-200421-000003-1234.txt.gz
(The “v8” prefix is there because I have arrived at this schema having tried several versions — 7, to be exact).
What about storage cost?
- An additional benefit of using date-based partitioning is that we can easily automate changing storage type to Glacier for folders older than some specified time, which will save S3 storage costs of the duplicate data.
- In the cloud, the storage costs are not something to worry about; the outgoing traffic and compute is where the problem is at. So move the compute to the data, not the other way around.
NOTE: Partitions do not equal timestamps
Partitioning is based on the file name. Records inside the file may have timestamps whose hour one greater than or one less than the partition hour, for obvious reasons. Thus, partitions are there to reduce the number of scanned records, but care should be taken when querying to not assume that the timestamps under year=2020/month=04/day=21/hour=00 all are in the 0th hour of 2020-04-21.
Discover metadata in Glue
Glue is an ETL service on AWS. One of the great features of Glue is crawlers that attempt to glean metadata from the logs. This is really convenient because it saves us the tedious step of defining the metadata manually.
So we set up a crawler. For explanation on how to do it, see the “Tutorial” link on the left hand side of this page:

However, it takes some time to get the configuration correct.
- We would want to exclude some logs because we know their format is not good for discovery (they are not straight-up JSON or CSV, etc; and, at the moment, custom SerDes are not supported by Athena) — but see below for exceptions. This is done in the “Data store” part of crawler configuration:

- We want Glue to treat new files of the same type as being different partitions of the same table, not create new ones. For example, given the partitioning convention we created above, these two paths:
- s3://logbucket/v8/wins/year=2020/month=04/day=21/hour=00/wins-200421-000003-1234.txt.gz
- s3://logbucket/v8/wins/year=2020/month=04/day=22/hour=11/wins-200422-000004-4321.txt.gz
Should be treated as partitions of table “wins”, not two different tables. We do this on the “Output” section of the crawler configuration as follows:

Once the crawler runs, we will see a list of tables created in Glue.
If here we see tables looking like parts of the partitioned path (e.g., year=2020, or ending with _txt_gz), it means the crawler got confused when discovering their structure. We are adding those to the crawler’s exclusion list, and will create their metadata manually. Fortunately, there are not that many such logs, and we can exclude them one by one.
Of course, while the crawler can recognize the file structure, it doesn’t know what to name the fields. So we can go and name them manually. While this is a tedious process, we don’t have to do that all at once – just do it on the as-needed basis.
We will want to keep the crawler running hourly so that new partitions (which get created every hour) are picked up. (This can also be done manually from Athena – or Hive — by issuing MSCK REPAIR TABLE command).
First useful Athena query
Looking now at Athena, we see that metadata from Glue is visible and we can run queries:

Woohoo! It works! I can do nice ad hoc queries. We’re done, right?
Almost. Unfortunately, for historical reasons, our logs are not always formatted to work with this setup ideally.
We could identify two key cases:
- Mostly CSV files:
- There are event prefixes preceding the event ID, even though the event itself is already defined by the log name. For example, bid:<BID_ID>, e.g.:
bid:0000-1111-2222-3333 - A CSV field in itself contains really two values. E.g., a log that is comma-separated into two fields: timestamp and “message”, which includes “Win: ” prefix before bid ID, and then – with no comma! – “price: ” followed by price. Like so:
04/21/2020 00:59:59.722,Win: a750a866-8b1c-49c9-8a30-34071167374e_200421-00__302 price:0.93
However, what we want to join on is the ID. So in these cases, we can use Athena views. For example, in these respective cases we can use:
CREATE OR REPLACE VIEW bids2 AS
SELECT "year", "month", "day", "hour",
"SUBSTRING"("bid_colon_bid_id", ("length"('bid:') + 1)) "bid_id"
FROM bids
and
CREATE OR REPLACE VIEW bids2 AS
SELECT "year", "month", "day", "hour",
"SPLIT_PART"("message", ' ', 3) "bid_id"
FROM wins
Now joins can be done on bid_id column, which makes for a more readable query.
- There are event prefixes preceding the event ID, even though the event itself is already defined by the log name. For example, bid:<BID_ID>, e.g.:
- The other case is a log that has the following format: a timestamp, followed by a comma, followed by JSON (an OpenRTB request wrapped in one more layer of our own JSON that augments it with other data). Which makes it neither CSV, nor JSON. Glue crawler gets confused. The solution is using RegEx SerDe, as follows:
And then we can use Athena’s JSON functions to deal with the JSON column, for example, to see distribution of requests by country:
Success! We can now use SQL to easily query our event logs.SELECT JSON_EXTRACT_SCALAR(request, '$.bidrequest.device.geo.country') country,
COUNT(*) cnt
FROM requests
GROUP BY
JSON_EXTRACT_SCALAR(request, '$.bidrequest.device.geo.country')
ORDER BY cnt DESC

Helpful links
- Amazon Athena User Guide on GitHub – official AWS guide but it appears to be organized better than the other
- Performance Tuning Tips for AWS Athena
I wish I didn’t have to: Decompiling Java
“I wish I didn’t have to” sounds like a category on its own, sort of like a complement to The Daily WTF. But, alas, I do — I need to understand what the differences are between two JARs, and I haven’t looked into Java decompilers since JAD (goes to show… something). But after some brief googling — Procyon rules! So here’s a script to do JAR diffs.
P.S. The humility of the author in designating a pretty good product as a 0 version (a propos — this is silly) led me to dig further into this project and it is cool stuff. Look forward to digging some more.
A look at app-ads.txt
Introduction
App-ads.txt is a follow-up to IAB’s ads.txt initiative aimed at increasing transparency in the programmatic ad marketplace. Related to it are a number of other initiatives and standards such as supply chain, payment chain, sellers.json, various things coming out of TAG group, etc. See last section for relevant links.
TL;DR: This standard allows an ad inventory buyer (DSP) to verify whether the entity selling the inventory (SSP) is authorized by the publisher to sell it. This is done by looking up the the publisher’s URL for an app (bundle) in the app store, and examining app-ads.txt file at that URL. The file lists authorized sellers of the publisher’s inventory, along with an ID that this publisher should be identified by in the reseller’s system (publisher.id in OpenRTB).
Terminology
Here, the words “publisher” and “developer” may be used interchangeably; ditto for “app” and “bundle”.
First pass implementation
The algorithm is fairly simple: for each app – aka bundle – of interest, grab the app publisher’s domain from the appropriate app store, fetch app-ads.txt file from that domain and parse it. But of course, in theory there is no difference between theory and practice, but in practice there is. In reality, there are some deviations from the standard and exceptional cases that had to be taken care of in the process.
As a first pass, we are running this process semi-manually; if the results warrant full automation, this can easily be accomplished. Here is what was done (more technical details can be found on GitHub):
- Bundle IDs and other information was retrieved from request log for the last few days (really, requests for all bids in May as of end of May 6), using a query to Athena. This comes to a total of:
- 1,144,377 bids
- 613,241 unique bundle IDs.
- 685,221 bundle-SSP combinations
- The result set, exported as CSV file is loaded into SQLite DB. The same SQLite DB is also used for caching of results.
- Go through the list of bundles with a Python script, appadsparser.py.While ads.txt standard provides the specification of how app stores should provide publisher information, only Google Play Store currently follows it. For Apple’s App Store, we crawl its search API’s lookup service, and, if not found there, directly the App Store’s page (though this appears to be a violation of robots.txt).
- The result is a semi-structured log. The summary is below.
Results Notes
Result codes
The following are result codes and their meaning:
- OK – The SSP we got the traffic on is authorized by the bundle publisher’s app-ads.txt for the publisher ID specified in request
- OK_GOOGLE – Google is authorized by the bundle publisher’s app-ads.txt. See below on explanation of why Google is special.
- PROBLEMS — Mismatch found between authorized SSPs and/or publisher IDs in app-ads.txt.
- NO_APPADS_TXT – Publisher’s website has no app-ads.txt file
- NOT_FOUND_IN_PLAY_STORE – bundle not found in Google Play Store. NOT_FOUND_IN_ITUNES – same for Apple App Store.
- NO_URL_IN_PLAY_STORE – cannot find publisher’s URL in Google Play Store. NO_URL_IN_ITUNES – same for Apple App Store.
- FACEBOOK_URL – publisher’s URL points to a Facebook page (this happens often enough that it warrants its own status) BAD_DEV_URL – publisher’s URL in an app store is invalid
- BAD_BUNDLE_ID – store URL (from the OpenRTB request) is invalid, and cannot be determined from the bundle ID either
Note on Google
NOTE: At the moment, there is no way to check the publisher ID for Google due to an internal issue. In other words, we cannot verify the following part of the spec:
Field #2 - Publisher’s Account ID - This must contain the same value used in transactions (i.e. OpenRTB bid requests) in the field specified by the SSP/exchange. Typically, in OpenRTB, this is publisher.id.
Given Google’s aggressive anti-fraud enforcement, we can for now stipulate that it would not run unauthorized inventory. There is still the possibility of fraud, of course. But in the below table we distinguish between bundles served via Google (where we do not check for publisher ID, just the presence of Google in app-ads.txt) and those served via other SSPs, where we cross-reference the publisher ID.
As a corollary of the above you will not see Google inventory under “PROBLEMS” status.
This gives a good sample:
Result code Count OK 5,693 OK_GOOGLE 29,330 PROBLEMS 361 NO_APPADS_TXT 7,653 NOT_FOUND_IN_PLAY_STORE 4,417 NOT_FOUND_IN_ITUNES 134 NO_URL_IN_PLAY_STORE 20,112 NO_URL_IN_ITUNES 16,168 FACEBOOK_URL 1,378 BAD_DEV_URL 4 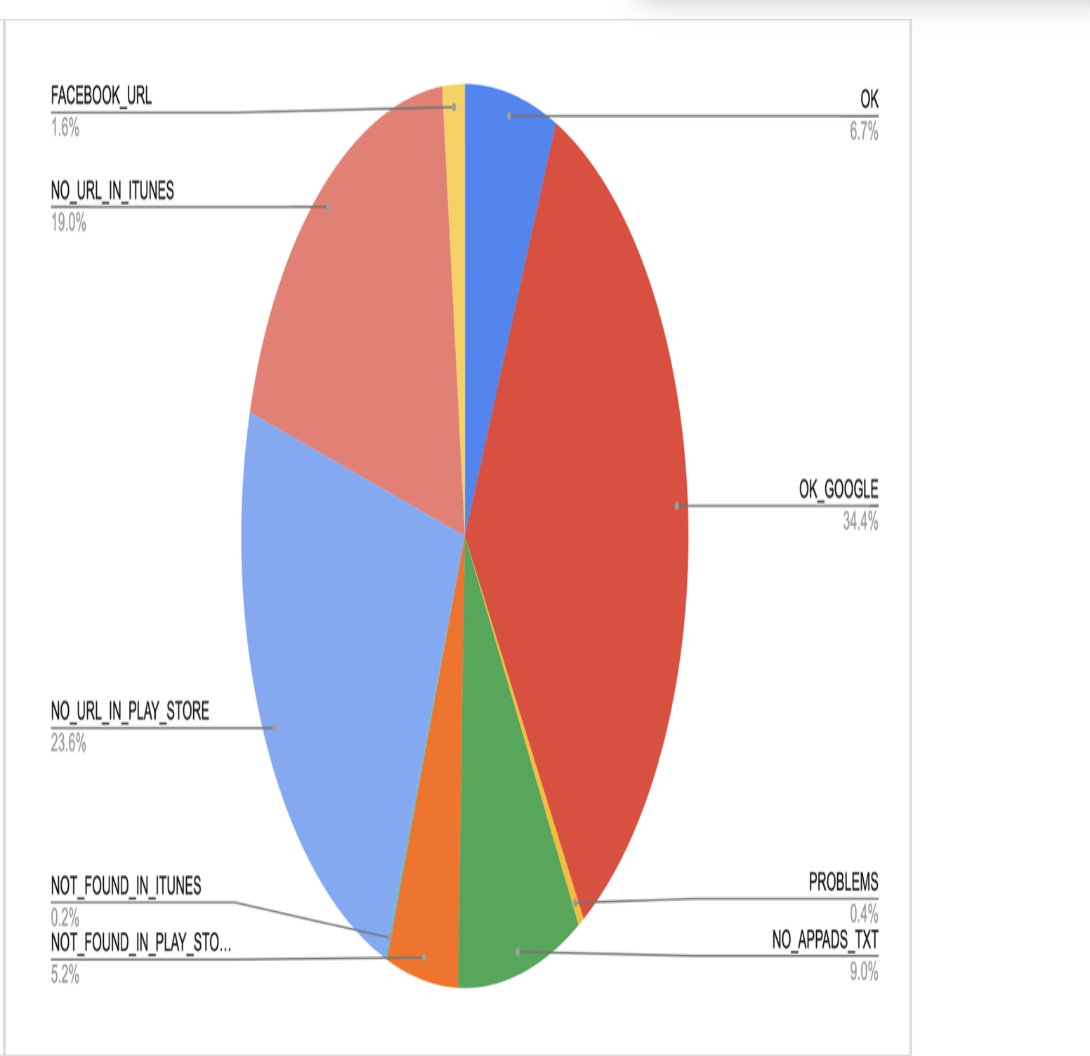
Summary of findings
It appears that due to not very high adoption of this standard at present (developer URLs not present in App Stores or app-ads.txt file not present on the developer domain), there is not much utility to it at the moment. However, as the adoption rate is increasing (see below), this is worth revisiting again. Also, consider that for this exercise we only used bids information – that is, not the sample of full traffic, but just what we have bid on. This may not be representative of the entire traffic also, and may be interesting to explore.
Consider also that the developer may well have the app-ads.txt file on the website, but if the website is not properly listed in the app store, we have no way of getting to it (yet SSPs may include those sites in their overall numbers, see, e.g., MoPub below).
What does the industry say?
- Google Play Store is reported to have only ~8% adoption. Worth quoting here is this section of the report:
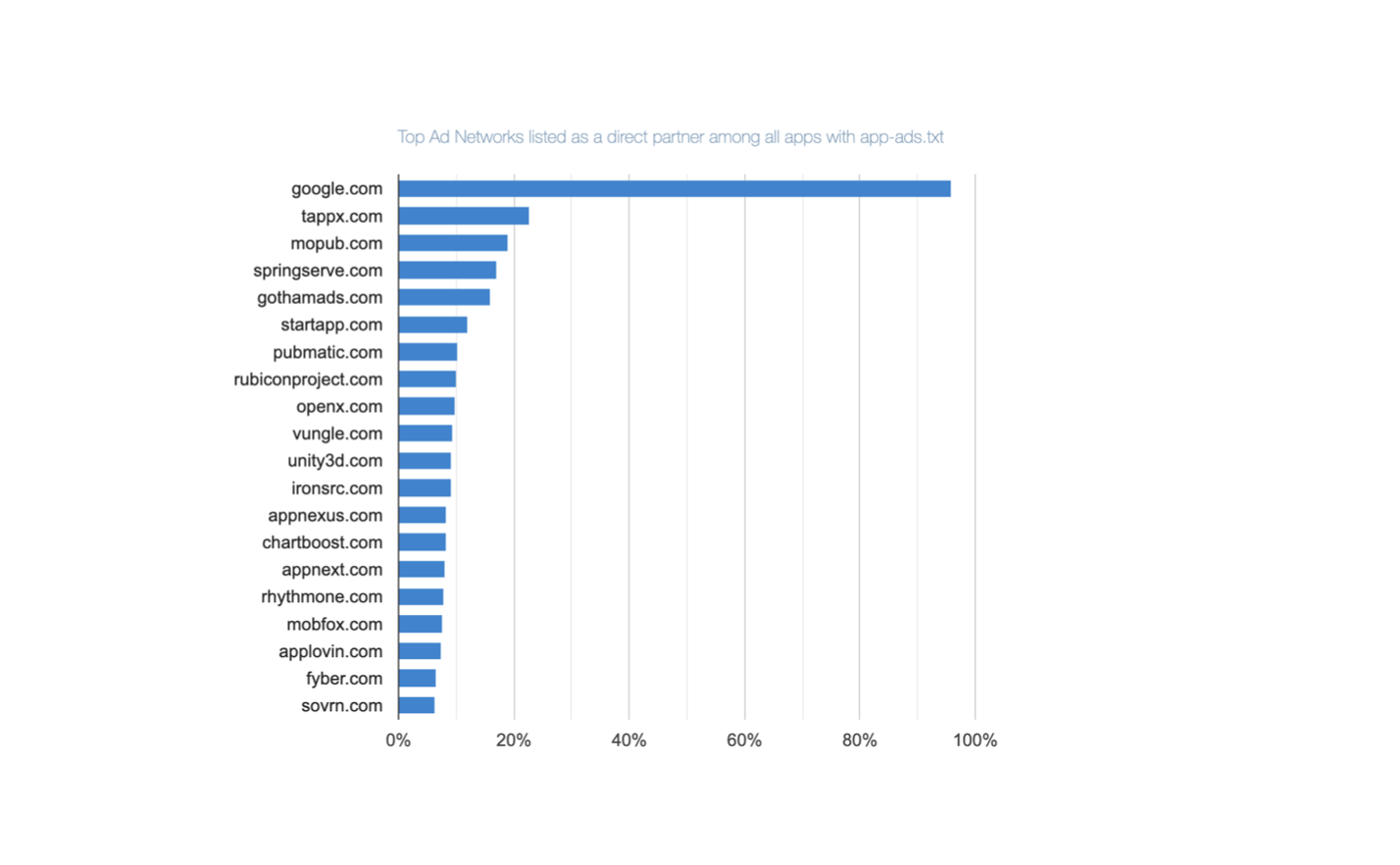
Who Are the Top ‘Direct’ Ad Partners Inside the App-Ads.txt in Google Play Apps?
Direct ad partners are those which have been granted direct permission by app developers to sell app ad space. That is, they are explicitly listed on the app’s “App-ads.txt” file. Google.com is listed as a direct ad partner on 95.87% of all “App-Ads.txt” files for Google Play apps. This makes it the most frequently mentioned direct ad partner for apps available on the Google Play.
- Pixalate’s 2019 app-ads.txt trends report is interesting:
- Doesn’t seem that app-ads.txt makes that much difference for IVT (invalid traffic) – apps with app-ads.txt have 18.7% of IVT vs 21.1% for those without (pg. 6), despite Pixalate dramatizing this 2.4 percentage point increase as a 13% increase (2.4/18.7 – lies, damn lies and statistics).
- It lists way higher numbers of adoption for Google Play Store apps than above but that is across top 1K apps.
- Increasing rates of adoption (~65% rise in Q4 2019 – pg.13)
- Unity, Ironsource, MoPub, Applovin, Chartboost – in that order – are in the top direct ad partners for Android apps (pg.18); MoPub, Unity, IronSource – in top direct AND resellers for iOS (pg.20)
- MoPub claims that “app-ads.txt file adoption exceeds 80% for managed MoPub publishers”. It’s unclear what the qualifier “managed” means. Sampling our data, we have issues with app-ads.txt on MoPub about 48% in total, breaking down as follows:
- No app-ads.txt: 11%
- No developer URL found in store: 22.5%
- Not found in app store: 13.7%
Not found?
Additionally, it is worth looking at the bundles that are flagged as NOT_FOUND_IN_PLAY_STORE or NOT_FOUND_IN_ITUNES – how come those cannot be found?
This does not have to be something nefarious, for example, based on spot-checking, it can be due to:
- Case-sensitivity. Play Store bundles are case-sensitive but an SSP may normalize them to lower case when sending (e.g., com.GMA.Ball.Sort.Puzzle becomes com.gma.ball.sort.puzzle)
- Some mishap like non-existent com.rlayr.girly_m_art_backgrounds being sent (but com.instaforall.girly_m_wallpapers exists)
But even if the majority of the NOT_FOUND errors are due to such discrepancies, not fraud, it means that currently app-ads.txt mechanism itself is de facto not very reliable.
Some other results
-
- Q: Are there any apps that present as different publishers on the same SSP?
-
- A: Not too many (about 8.6%), but even so for most important apps it is at most 2-3 – and even at long tail the max is 10 publisher IDs. This, though, can still account for some app-ads.txt PROBLEMs as seen above)
Related documents, standards and initiatives
-
- App-ads.txt spec (which builds on ads.txt spec). Real life example – app-ads.txt on CNN’s site.
- Supply chain object
- Payment chain
- Sellers.json spec and related page
- Sellers.json and supply chain FAQ
- Pixalate – 2019 App Ads.txt Trends Report.pdf
- Google Play Store is reported to have only ~8% adoption. Worth quoting here is this section of the report:
