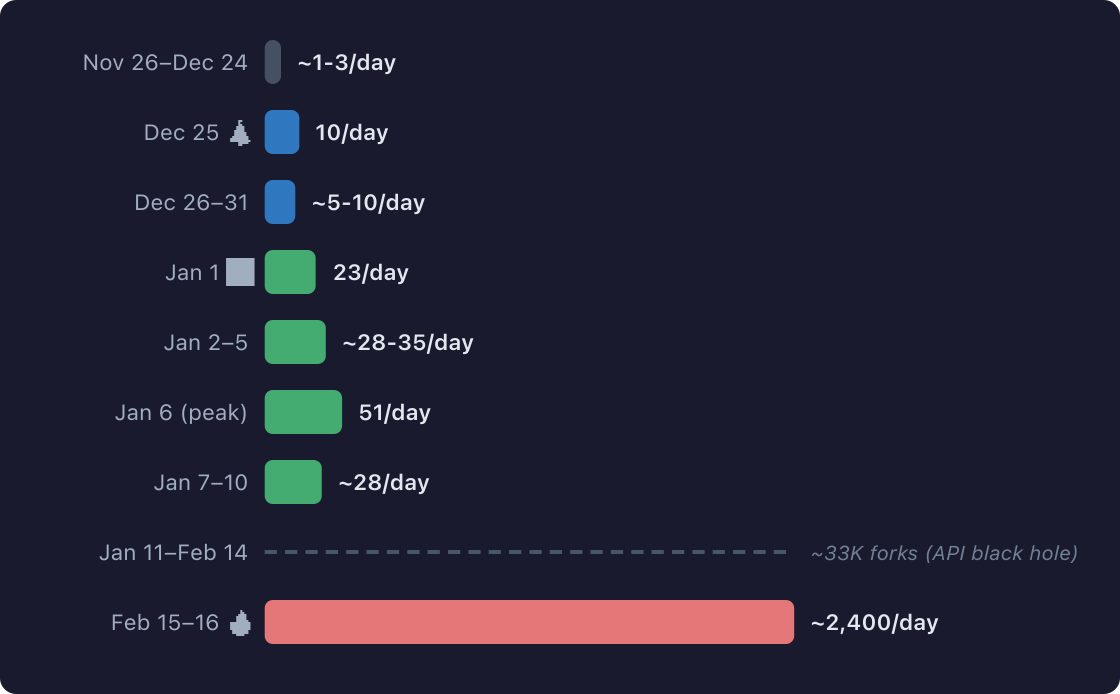
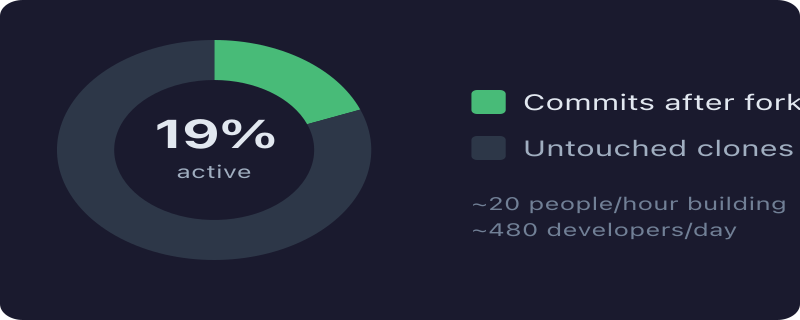
Two days ago we published a quick look at OpenClaw’s fork explosion — 34,600 forks, sampled from the bookends of GitHub’s API, with a 33,000-fork black hole in the middle. We were upfront about it: “This was a 30-minute investigation, not a thesis.”
This is the thesis.
We went back and scraped all 36,915 forks (the number grew while we were counting). Every single one. Plus 9,423 pull requests. Three graphs, no black holes, no excuses.
Graph 1: The hockey stick that wasn’t quite a hockey stick
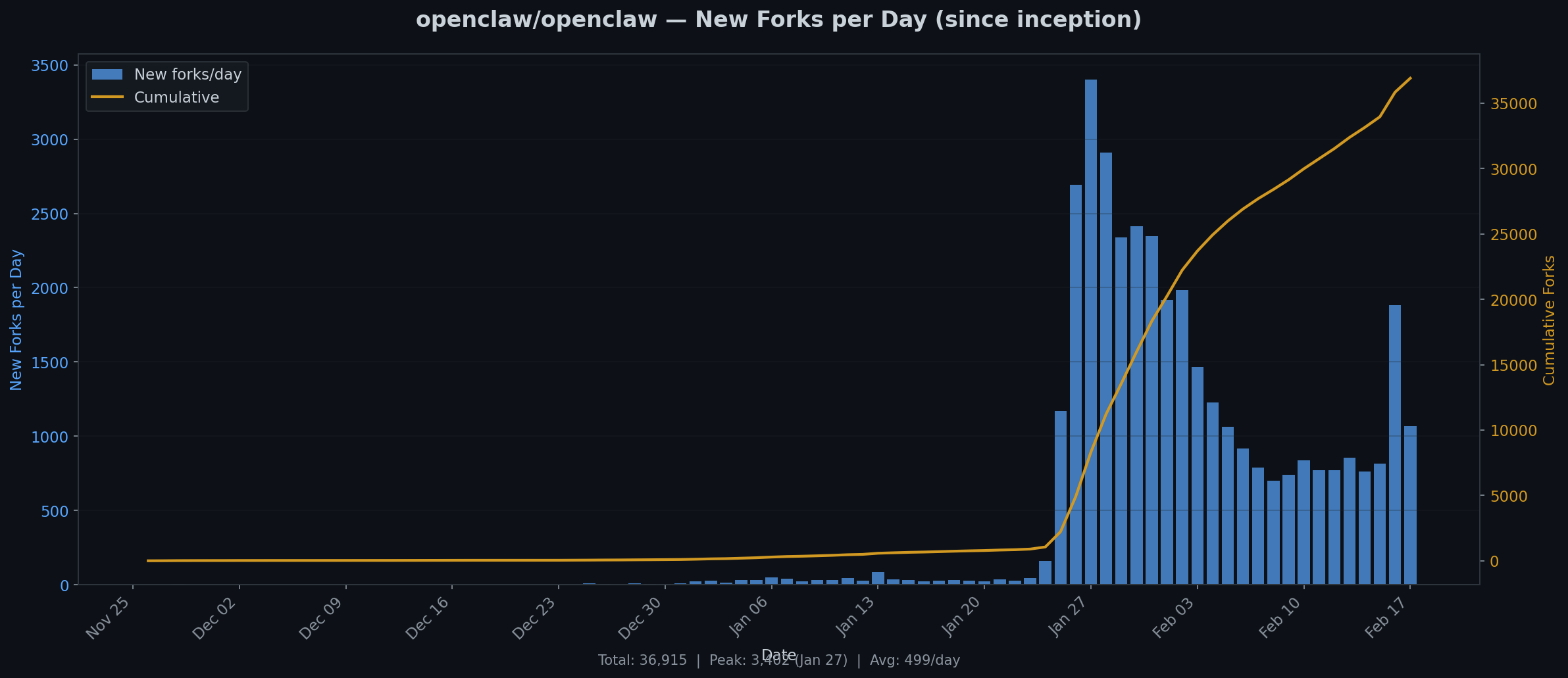
36,915 total forks. Peak: 3,402 on January 27. Average: 499/day.
The first fork appeared November 26, 2025. For nearly two months: nothing. A handful of early adopters per day, the kind of people who read Hacker News at 2am and clone things “to look at later.”
Then something happened around January 20.
Daily forks went from ~50 to over 1,000 in three days. By January 27, it hit 3,402 in a single day. That’s one fork every 25 seconds, sustained for 24 hours.
But here’s what the full data shows that the sample didn’t: it’s already declining. The peak was January 27. By mid-February, we’re down to about 1,000/day — still enormous, but the exponential phase lasted exactly one week. What we’re in now is the long tail. The viral moment came, the viral moment is going.
The cumulative curve tells the same story: a flat line, a vertical cliff, and then an inflection into deceleration. Classic viral adoption. The question isn’t whether it will keep growing — it will. The question is whether it levels off at 40,000 or 400,000.
Graph 2: Who actually builds anything?
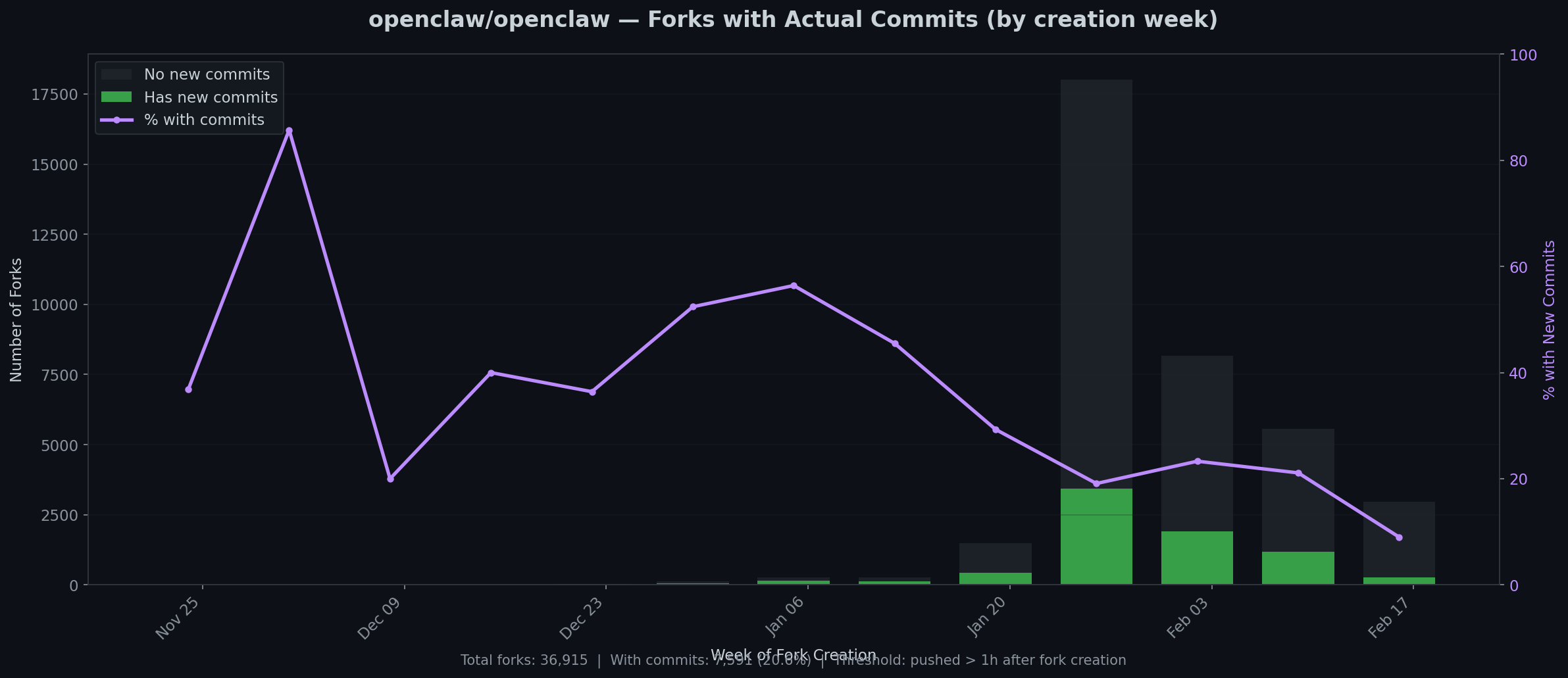
7,591 of 36,915 forks (20.6%) have new commits. Threshold: code pushed more than 1 hour after forking.
This is the graph that matters.
In the early days — November, December — the commit rate was absurd. 60-90% of forks showed real work. These were people who forked because they intended to build. Small community, high signal.
Then came January’s tidal wave, and the ratio cratered. At peak volume, only about 10-20% of forks have any commits at all. The rest are what they’ve always been: GitHub bookmarks. One click, zero intention.
But zoom out from percentages and look at absolute numbers: even at 10%, that’s 300-500 people per day writing actual code on top of OpenClaw. The most recent week shows roughly 1,200 committed forks out of about 5,500 new ones. That’s a healthy project by any measure. It’s just a healthy project buried under 80% noise.
The trend line tells you something about open-source psychology: the harder a project is to use, the higher its commit rate. When OpenClaw was obscure, only competent developers found it. Now that it’s famous, everybody forks it and almost nobody builds anything. Same pattern as every framework that hits the front page of Reddit.
Graph 3: Who gives back?
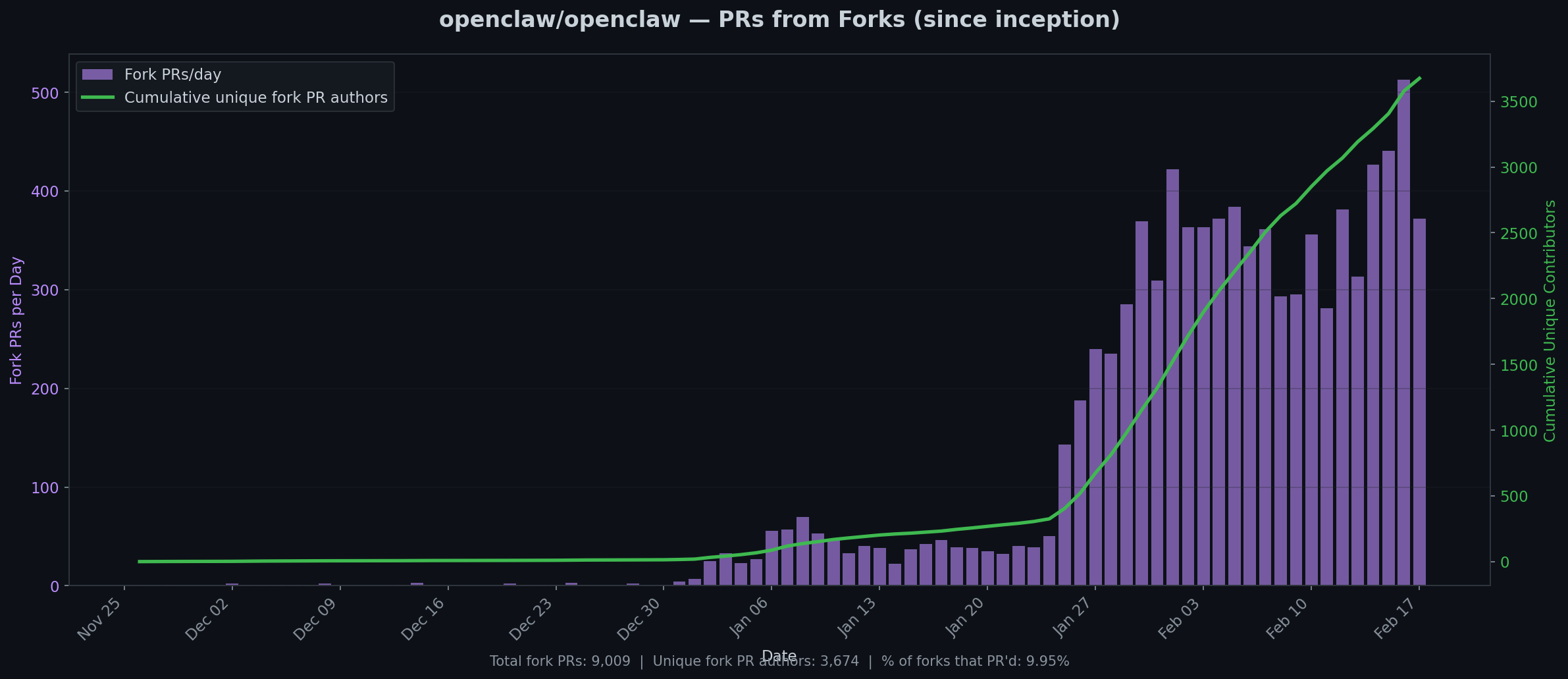
9,009 fork PRs from 3,674 unique authors. 9.95% of forks ever sent a PR upstream.
One in ten. That’s actually remarkable for open source.
For context: most popular GitHub projects see PR rates of 1-2% of their fork base. React, with its 10:1 star-to-fork ratio, gets far fewer contributors relative to its fork count. OpenClaw’s 10% is unusually high — partly because the project is young and actively soliciting contributions, partly because the architecture (plugins, extensions, MCPs) makes it easy to contribute without touching core code.
The daily PR count has been climbing steadily: from single digits in December, to 50/day in mid-January, to a sustained 300-500/day now. Cumulative unique contributors crossed 3,500 and show no signs of flattening. Whatever is happening to the fork rate, the contribution rate is still accelerating.
That divergence — declining forks, accelerating PRs — is the best signal in this entire dataset. It means the project is transitioning from “thing people try” to “thing people commit to.”
What we got wrong in Part 1
Our original sample of the 100 newest forks found 19% activity. The full dataset says 20.6%. We were within a rounding error, which is either a testament to sampling theory or dumb luck. Probably both.
What the sample couldn’t show was the shape of the curve — the early period of 60-90% engagement that collapsed as volume exploded. The 20% number is real, but it’s an average across two very different populations: serious developers who forked early, and a much larger wave of tourists who forked because it was trending.
We also estimated “~2,400 forks/day” based on a snapshot. The real peak was 3,402. And by now it’s fallen to about 1,000. The snapshot caught a number that was already past its peak but hadn’t decayed enough to notice.
The numbers that matter
Forget 36,915 forks. Here’s what actually counts:
- 7,591 forks with real commits — people building things
- 3,674 unique PR authors — people giving back
- ~500 PRs/day at current pace — and growing
That’s not a fork explosion. That’s a contributor ecosystem forming in real time. The other 29,324 forks are scenery.
We’ll explain shoelace eventually. Promise.
Full dataset: 36,915 forks and 9,423 PRs scraped from the GitHub REST API v3 on February 17, 2026. All forks paginated (no sampling). Commit activity measured by comparing pushed_at to created_at with a 1-hour threshold to filter initial fork sync. PR data from GitHub’s search API.