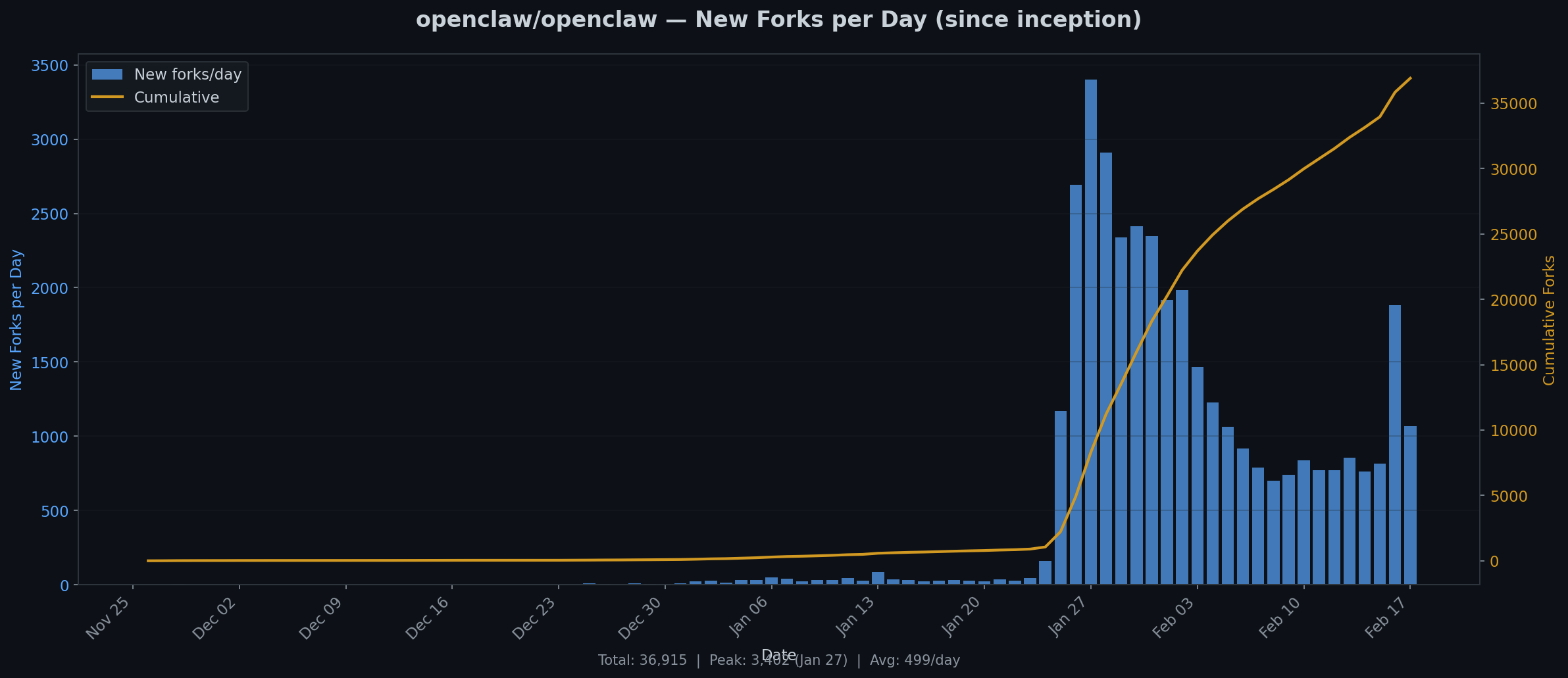
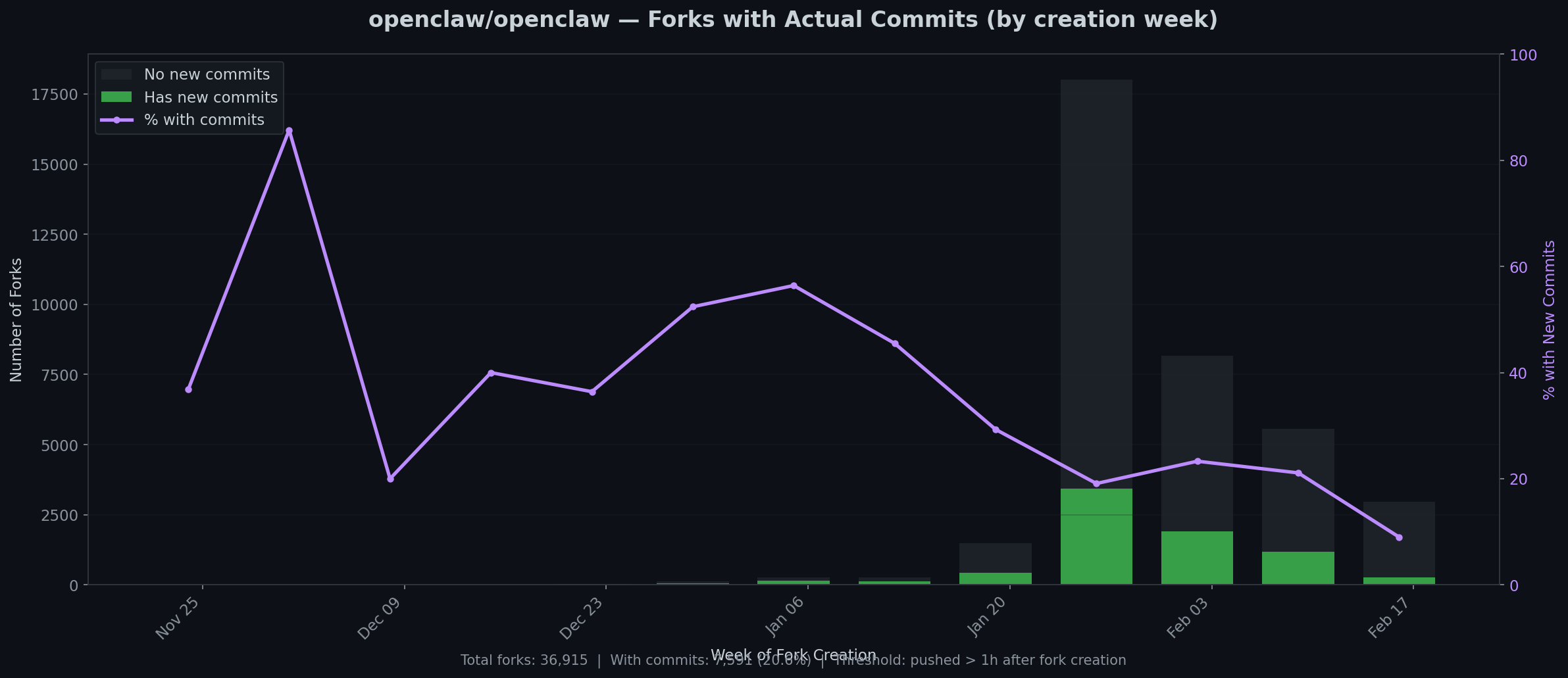
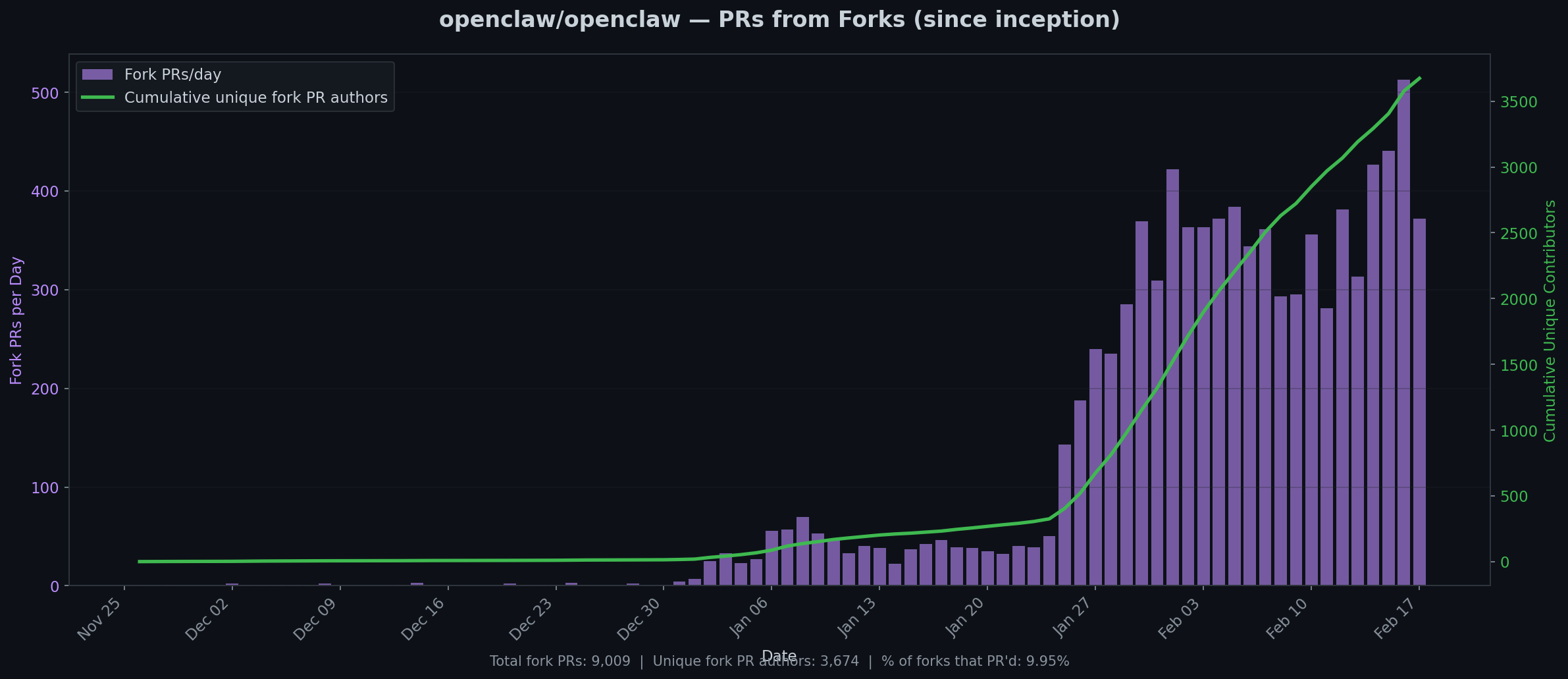
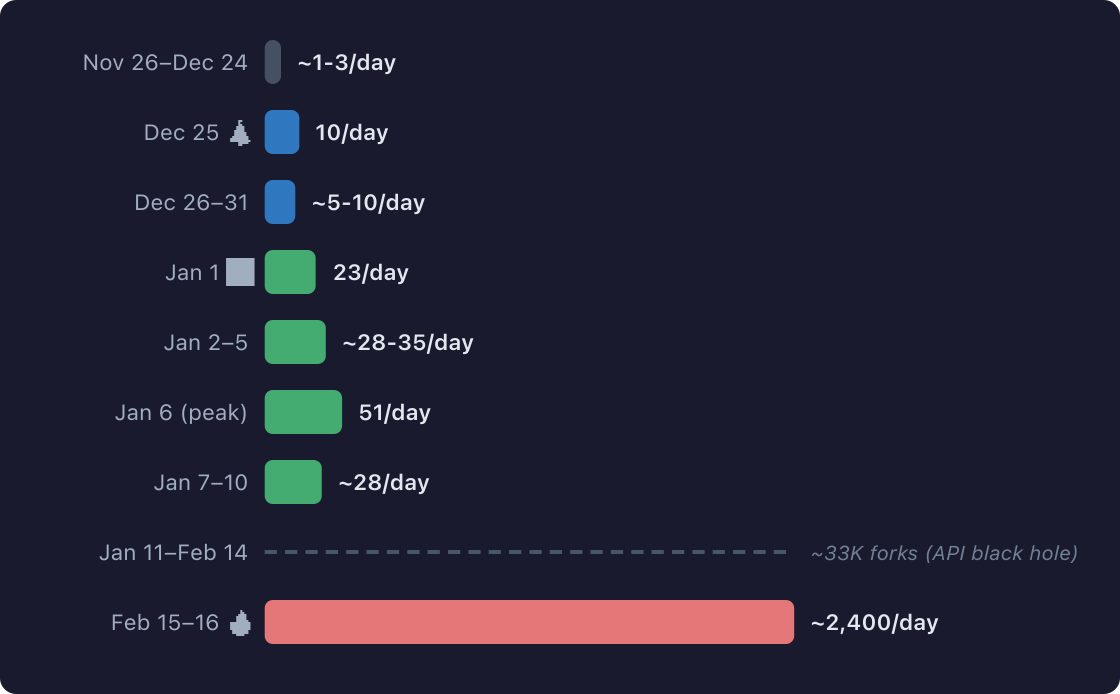
A follow-up to our February 13 comparison of llm-tldr and voitta-rag.
Part I: voitta-rag — From Code Search to Knowledge Platform
When we last looked at voitta-rag, it was a solid hybrid search engine for codebases — index your repos, search via MCP, get actual code chunks back. Twelve days and 11 commits later, it’s become something broader: a self-hosted knowledge platform that indexes not just code but your entire work graph.
Here’s what landed since February 13.
Enterprise Connectors: Jira, Confluence, SharePoint
The biggest expansion is connector coverage. voitta-rag now syncs from Jira, Confluence, and SharePoint alongside the existing Git, Google Drive, Azure DevOps, and Box integrations.
Jira and Confluence support both Cloud (API token with Basic auth) and Server/Data Center (PAT with Bearer auth), selectable via dropdown in the UI — a detail that matters because plenty of enterprises still run on-prem Atlassian. Cloud uses the v3 search endpoint (v2 is deprecated), and Confluence Cloud correctly routes through /wiki/rest/api.
SharePoint got a full global sync implementation. And on the UI side, both Jira projects and Confluence spaces now use multi-select dropdown widgets — you can cherry-pick specific projects or select “ALL” to dynamically sync everything, including future additions. Practical touch: JQL project keys are now quoted to handle reserved words like IS that would otherwise break queries.
Time-Aware Search
Search results are no longer timeless. voitta-rag now tracks source timestamps — created_at and modified_at — propagated from every remote connector through a .voitta_timestamps.json sidecar file into the indexing pipeline and vector store.
This enables time range filtering on the MCP search tool via date_start/date_end parameters. “What changed in the last week?” is now a first-class query. For an AI assistant trying to understand recent activity across repos, Jira boards, and Confluence spaces simultaneously, this is a significant upgrade.
Anamnesis: Persistent Memory for AI Assistants
The most architecturally interesting addition. Anamnesis (Greek for “recollection”) gives AI assistants a persistent memory layer backed by voitta-rag’s vector store.
Six new MCP tools let an assistant create, retrieve, update, delete, like, and dislike memories. The like/dislike mechanism adjusts relevance scoring — memories the assistant finds useful surface more readily over time, while unhelpful ones fade. It’s essentially a learning loop: the AI assistant builds up a knowledge base of its own observations and decisions, searchable alongside the actual indexed content.
This turns voitta-rag from a read-only knowledge base into a read-write one — the assistant doesn’t just consume context, it contributes to it.
Per-User Search Visibility
A multi-tenancy feature: users can now enable or disable folders for their own search scope without affecting other users. If you’ve indexed 50 repos but only care about 5 for your current task, you toggle the rest off. The MCP server respects these per-user visibility settings, so AI assistants scoped to different users see different slices of the same knowledge base.
More File Types
The indexing pipeline now handles AZW3 (Amazon Kindle) files, joining the existing support for DOCX, PPTX, XLSX, ODT, ODP, and ODS. Not the most common format in a work context, but it signals that voitta-rag is thinking beyond code and office docs toward general document ingestion.
The Bigger Picture
Two weeks ago, voitta-rag was a code search tool. Now it indexes your Git repos, Google Drive, SharePoint, Jira, Confluence, Box, and Azure DevOps — with time-aware search, per-user scoping, and persistent AI memory. The trajectory is clear: it wants to be the single search layer across everything your team produces, exposed to AI assistants via MCP.
The self-hosted angle remains the key differentiator. Nothing leaves your network. For teams where that matters (and increasingly, it does), this is starting to look like a serious alternative to cloud-hosted RAG services.
Part II: voitta-yolt — You Only Live Twice
Brand new from Voitta AI today: voitta-yolt (You Only Live Twice) — a safety analyzer for Claude Code that statically analyzes Python scripts before execution.
The Problem
Claude Code can write and run Python scripts. That’s powerful and dangerous in equal measure. By default, you either pre-approve all Python execution (fast but risky) or manually approve each script (safe but maddening). Neither is great.
How YOLT Works
YOLT registers as a Claude Code PreToolUse hook on the Bash tool. When Claude Code runs python3 script.py, YOLT intercepts the command, parses the Python AST, and walks every function call against a configurable rule set:
- Safe scripts (pure computation, data parsing, read-only operations) get auto-approved — no permission prompt.
- Destructive scripts (file writes, AWS mutations, subprocess calls, network POSTs, database connections) get flagged for human review with specifics about what was detected, including the source line content.
Zero external dependencies — it’s pure stdlib (ast, json, fnmatch, shlex). AST parsing is near-instant, so there’s no perceptible delay.
The Rule System
The default rules are sensible and well-structured:
- AWS boto3:
describe/list/get/head→ safe.delete/put/create/terminate→ destructive. Rules scope viatrigger_imports, socache.delete_item()in a non-AWS script won’t false-positive. - File I/O:
open()in write modes,os.remove,shutil.rmtree→ destructive. Read-only access is fine. - Subprocess: Always flagged.
subprocess.run,os.system, the lot. - Network:
requests.get→ safe.requests.post/put/delete→ destructive. - Database: Connection creation → flagged for review.
A curated list of safe imports (json, csv, re, datetime, pathlib, hashlib, and ~50 others) means scripts that only use standard library data-processing modules sail through without interruption.
Custom rules go in ~/.claude/yolt/rules.json and merge with defaults — you can add safe methods, define new categories with their own trigger_imports, and use glob patterns (fetch_*, drop_*).
One Important Gotcha
If you have Bash(python3:*) in your Claude Code settings.local.json allow list, YOLT’s hook never fires — static allow rules take precedence over PreToolUse hooks. YOLT replaces the need for that allow rule entirely: safe scripts get auto-approved by the hook itself.
Why This Matters
The design philosophy — “false positives OK, false negatives not” — is the right one for a safety tool. It’s the security principle of fail-closed applied to AI code execution.
YOLT is small (527 lines across 6 files in the initial commit), focused, and immediately useful. If you’re letting Claude Code run Python, this is the kind of guardrail that should exist by default.
Wrapping Up
voitta-rag is evolving from a code search tool into a self-hosted knowledge platform with enterprise connectors and AI memory. voitta-yolt tackles a different but equally practical problem: making AI code execution safer without making it slower.